The holistic modeling of human behavior is central to a wide range of disciplines. While Large Language Models (LLMs) have raised the prospect of serving as general-purpose user-simulators, the empirical basis for assessing their capabilities remains systematically insufficient. Existing benchmarks suffer from critical limitations:
(1) They are confined to isolated scenarios with narrow action spaces (e.g., exclusively focusing on video browsing or e-commerce dialogue).
(2) Such narrow focus overlooks the holistic, interconnected nature of authentic human decision-making and preferences.
(3) They fail to assess whether LLMs can transcend fragmented data to model long-horizon causal structures.
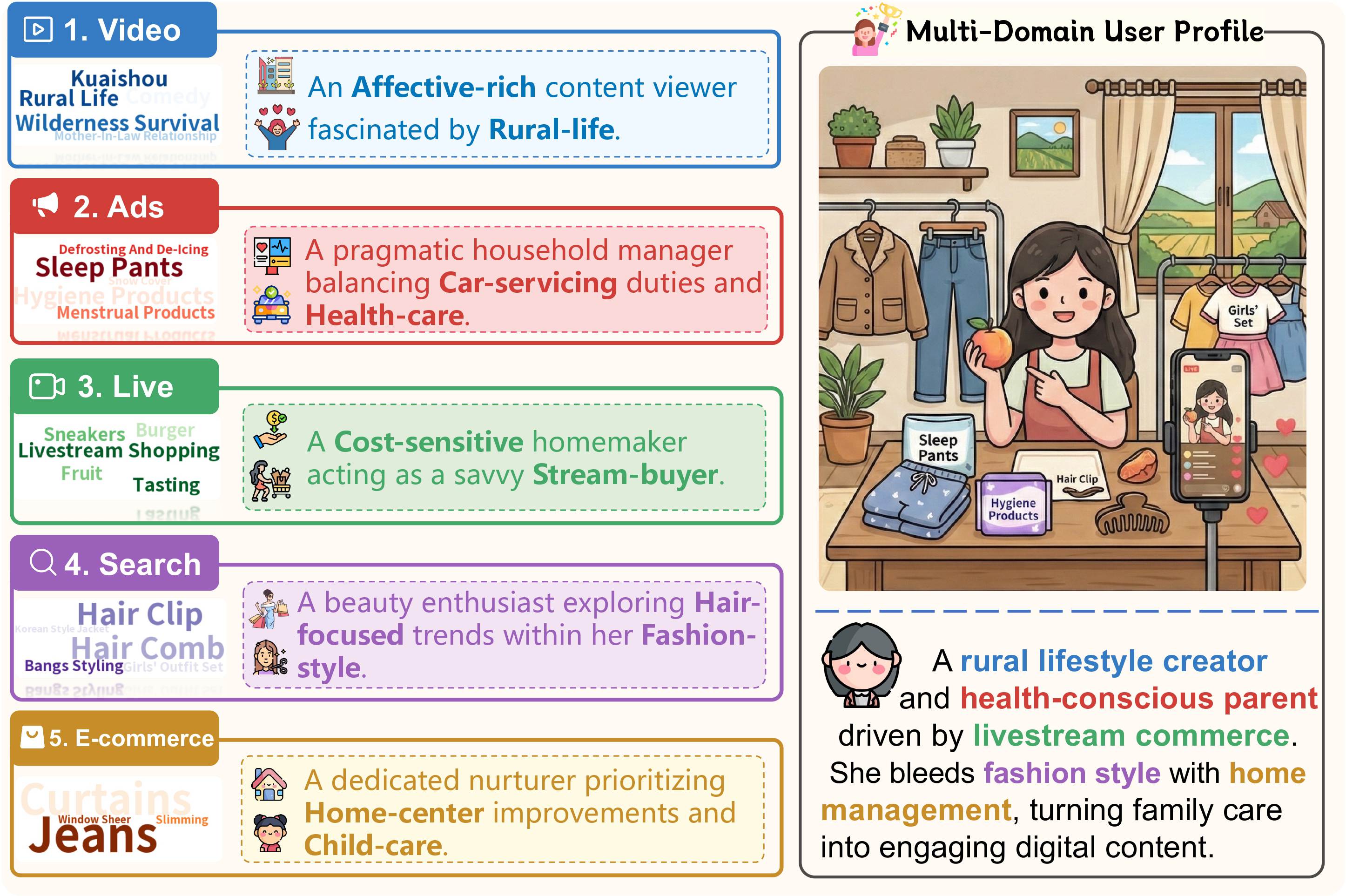
To bridge this gap, we present OmniBehavior, the first user simulation benchmark built entirely on real-world data that simultaneously captures long-horizon, cross-scenario, and heterogeneous behavioral patterns. Collected from Kuaishou, OmniBehavior aggregates complete interaction traces from representative users over a three-month period across 5 diverse scenarios.
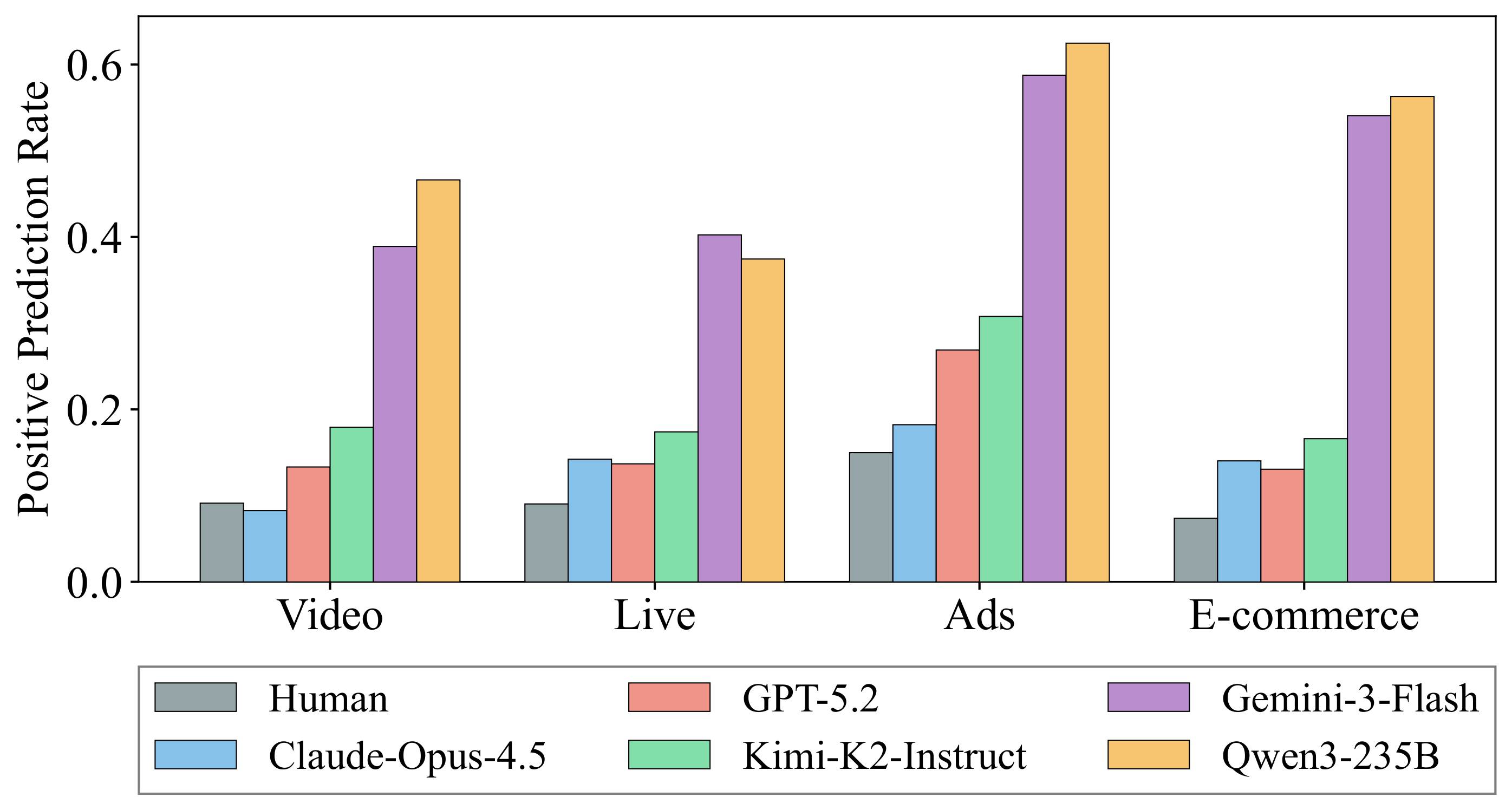
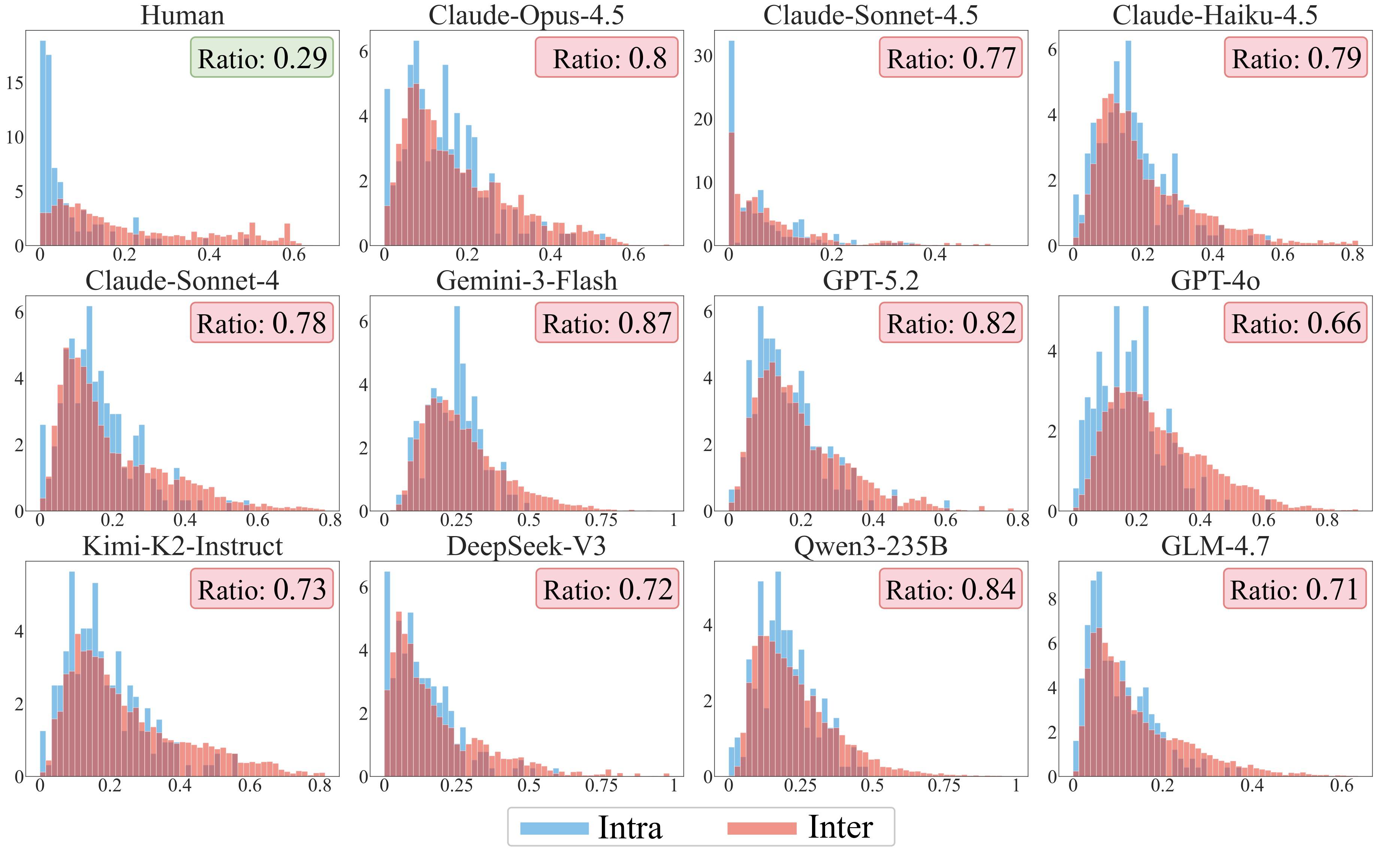
Comprehensive evaluation of current state-of-the-art closed and open-source LLMs reveals substantial limitations. For instance, the best-performing LLM (Claude-4.5-Opus) achieves an overall score of only 44.55, and F1 scores on binary behavior prediction for most models do not exceed 40%. This proves that current LLMs struggle to accurately simulate complex, long-horizon user behavior traces.
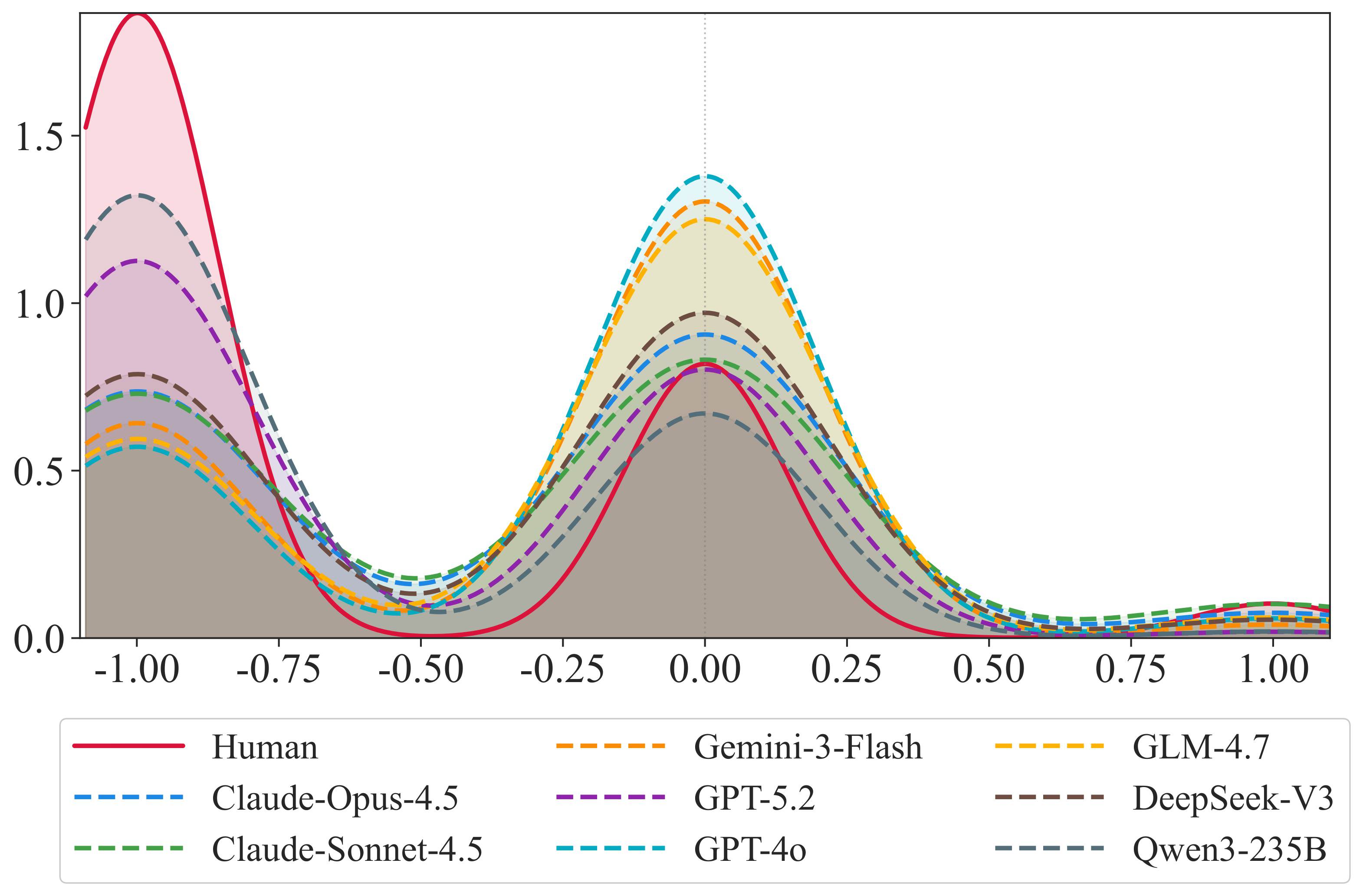
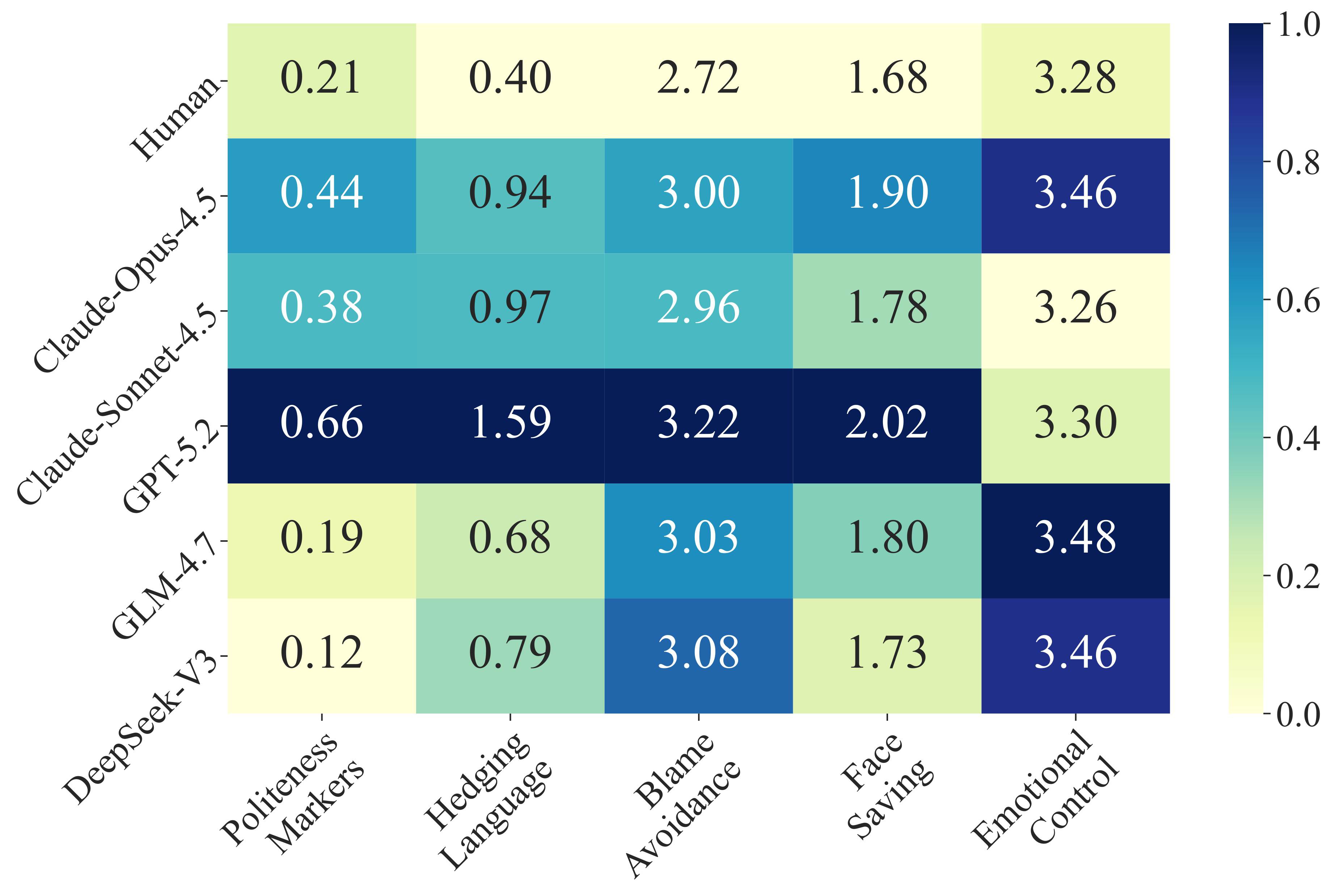
Crucially, our study uncovers a fundamental structural bias in current LLM simulators: they converge toward a "positivity-and-average" representation. This Utopian bias and hyper-activity blur individual-specific differences, discarding long-tail behaviors and negative feedback signals. OmniBehavior provides a vital framework to guide the genuine modeling of real human diversity.
(1) They are confined to isolated scenarios with narrow action spaces (e.g., exclusively focusing on video browsing or e-commerce dialogue).
(2) Such narrow focus overlooks the holistic, interconnected nature of authentic human decision-making and preferences.
(3) They fail to assess whether LLMs can transcend fragmented data to model long-horizon causal structures.
To bridge this gap, we present OmniBehavior, the first user simulation benchmark built entirely on real-world data that simultaneously captures long-horizon, cross-scenario, and heterogeneous behavioral patterns. Collected from Kuaishou, OmniBehavior aggregates complete interaction traces from representative users over a three-month period across 5 diverse scenarios.
Comprehensive evaluation of current state-of-the-art closed and open-source LLMs reveals substantial limitations. For instance, the best-performing LLM (Claude-4.5-Opus) achieves an overall score of only 44.55, and F1 scores on binary behavior prediction for most models do not exceed 40%. This proves that current LLMs struggle to accurately simulate complex, long-horizon user behavior traces.
Crucially, our study uncovers a fundamental structural bias in current LLM simulators: they converge toward a "positivity-and-average" representation. This Utopian bias and hyper-activity blur individual-specific differences, discarding long-tail behaviors and negative feedback signals. OmniBehavior provides a vital framework to guide the genuine modeling of real human diversity.
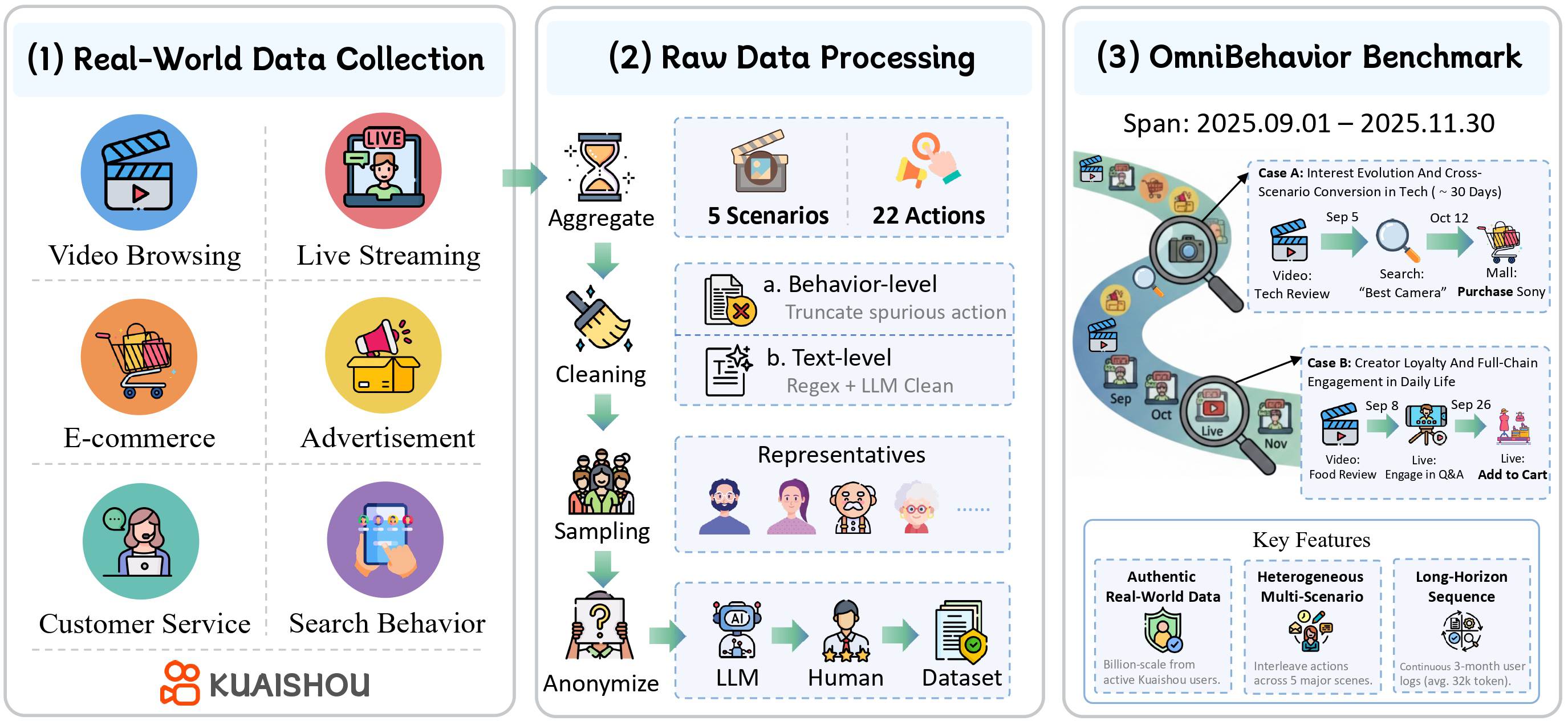
Overview of OmniBehavior, a real-world comprehensive benchmark for evaluating LLM-based user simulators. The benchmark is constructed in three stages:
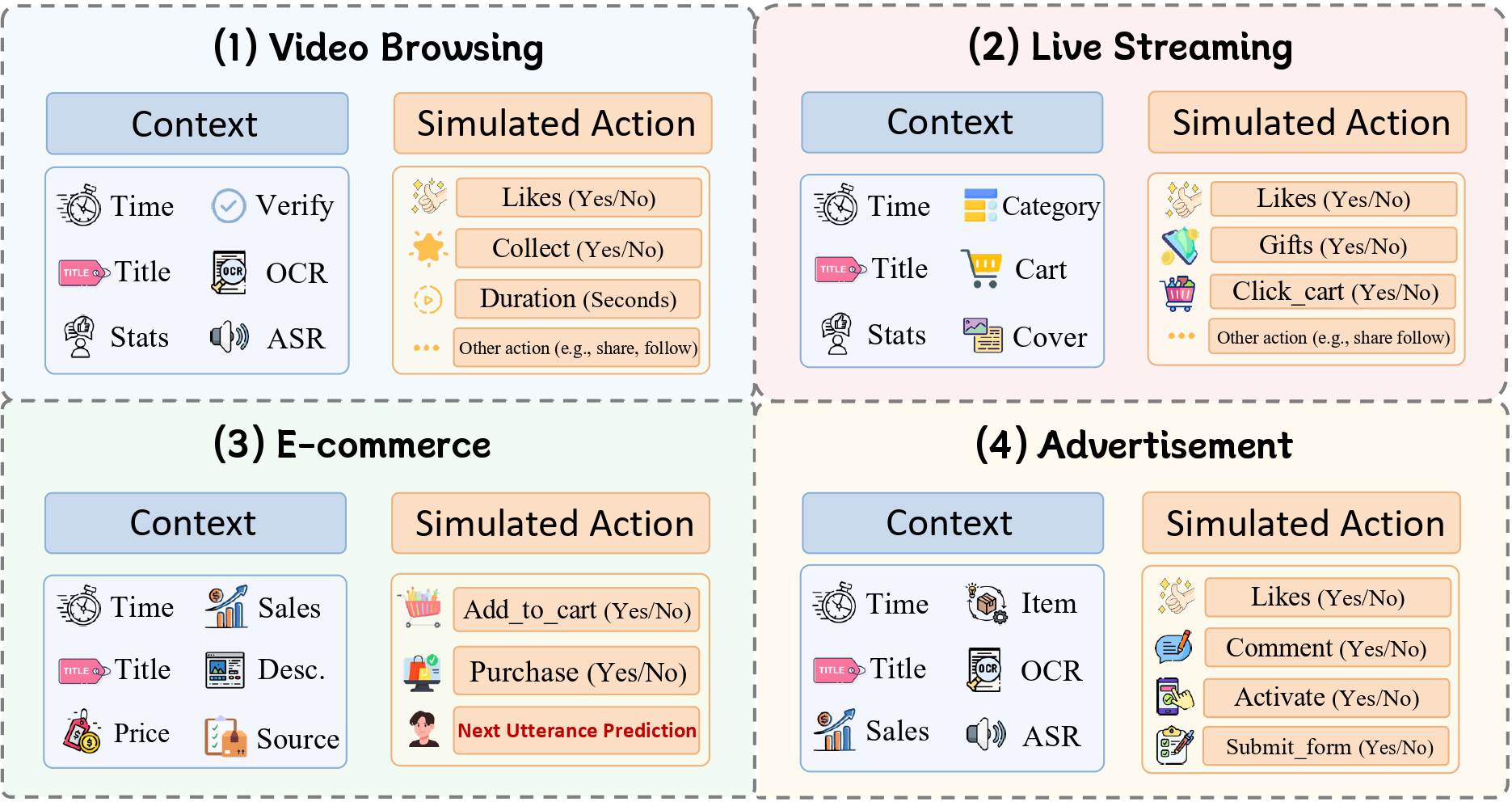
(1) Data Collection: aggregation of real-world logs from Kuaishou platform across five major scenarios.
(2) Data Processing: multi-modal fusion, two-level cleaning, representative sampling, and anonymization.
(3) Benchmark Construction: the resulting dataset captures long-horizon, cross-scenario behavior traces, providing as a high-fidelity testbed for evaluating LLM-based user simulators in real-world industrial settings.